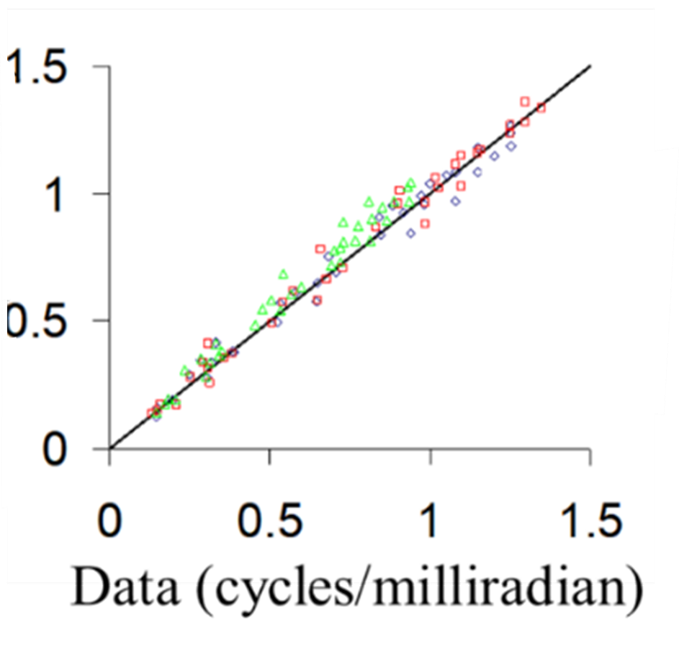
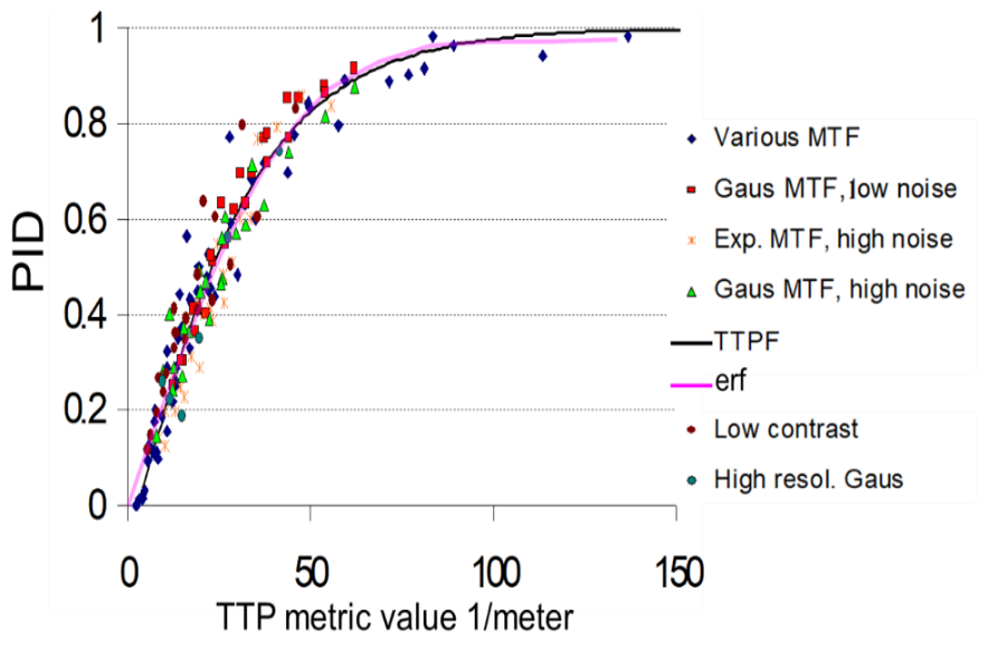
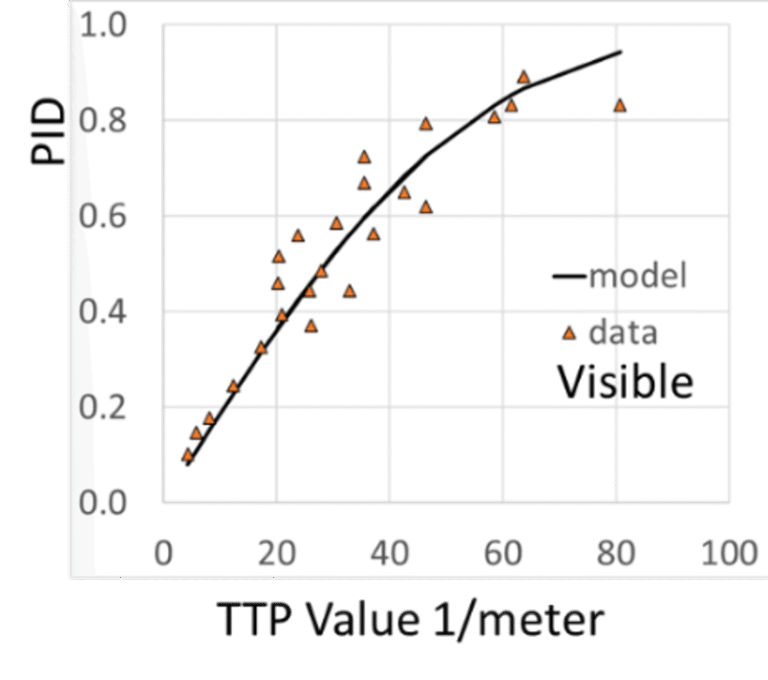
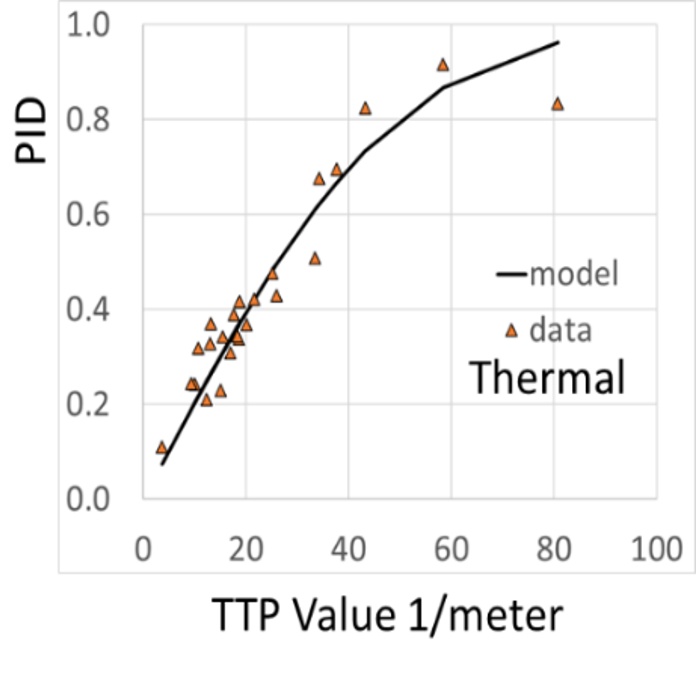
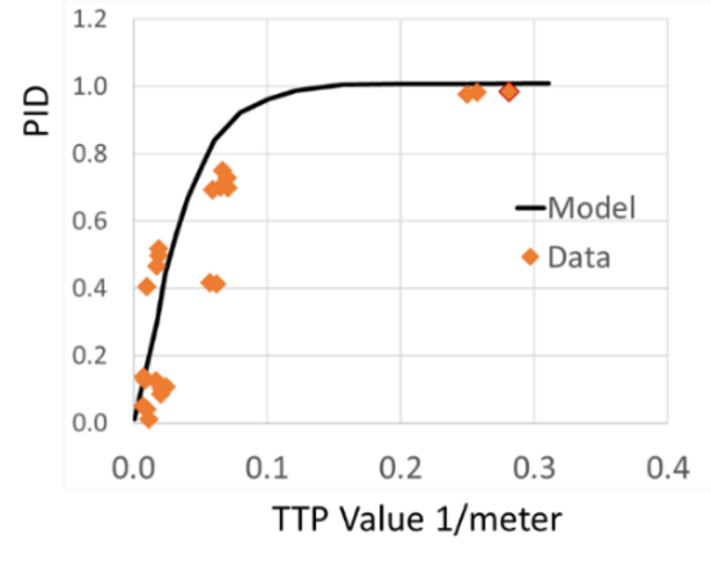
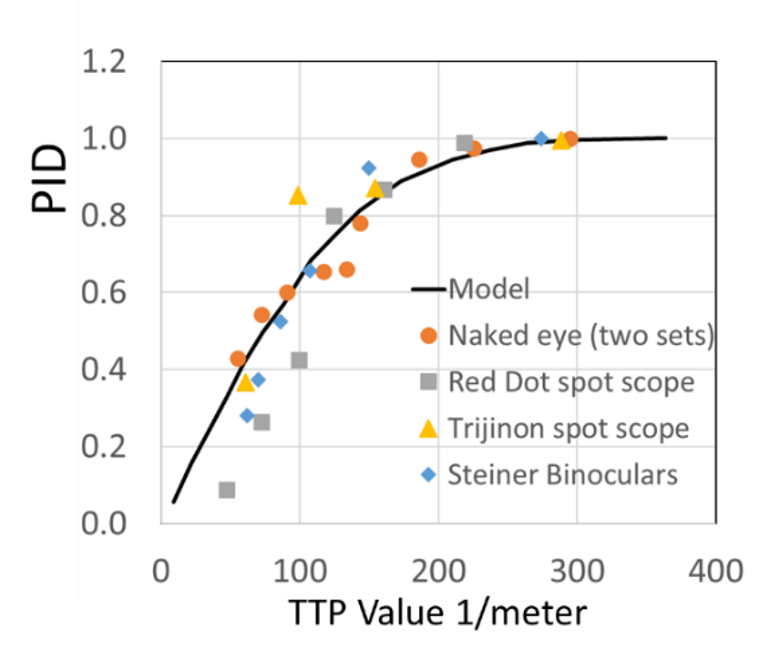
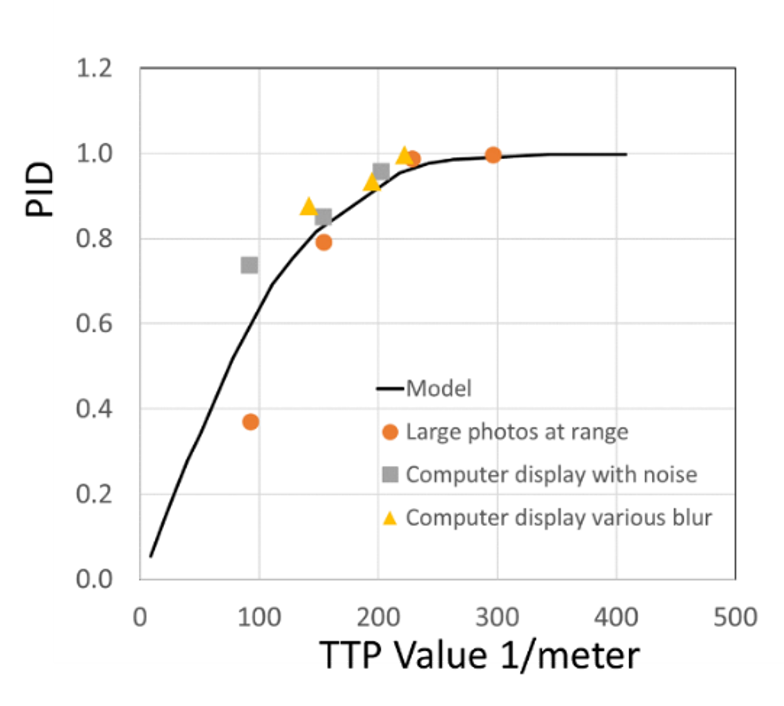
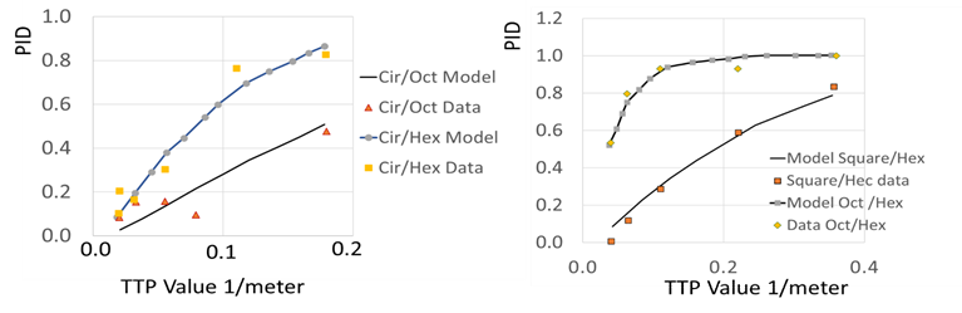
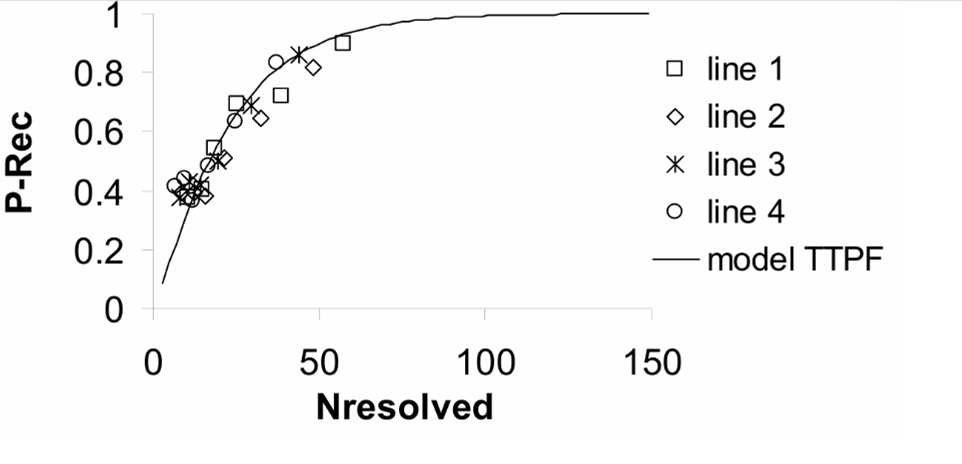
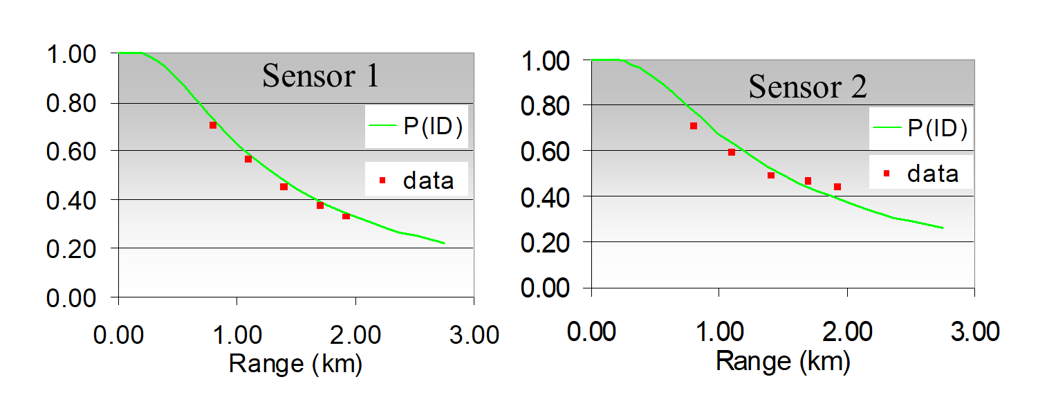
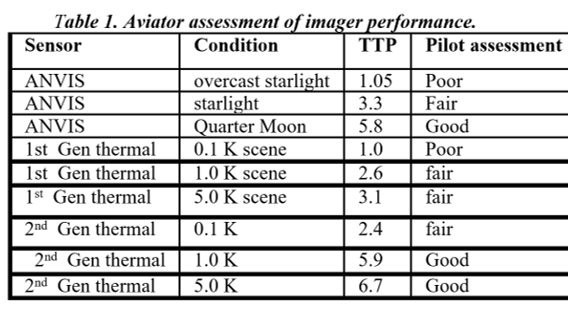
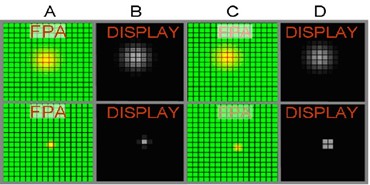
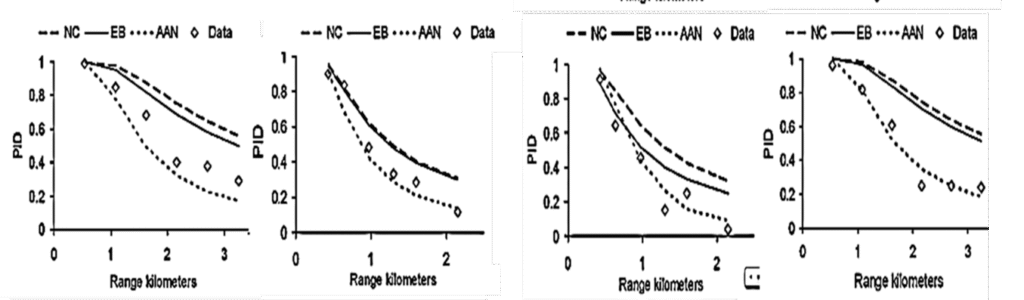
NVThermIP modeled thermal imagers and was part of a set of models that included an image intensifier model. Over the last forty years, Army aviators have flown with imager intensifiers (ANVIS) and both first and second generation thermal imagers [24]. The table shows TTP predictions for pilotage utility and the results of pilot surveys. TTP predicts aviator experience
with pilotage sensors. This data for the original TTP and not NVIPM.